JavaScript面试题
箭头函数与普通函数的区别
箭头函数是匿名函数,不能作为构造函数,故不可使用
newlet fn = () => { console.log(123); } fn(); // 123 let bar = new fn(); // Uncaught TypeError: fn is not a constructor箭头函数不绑定
arguments,取而代之用rest参数解决let fn = () => { console.log(arguments); } fn(11, 22); // Uncaught ReferenceError: arguments is not defined let bar = (...argsArray) => { console.log(argsArray); } bar(33, 44); // [33, 44]箭头函数不绑定
this,会捕获其所在的上下文的this值,作为自己的值let person = { name: 'leo', skill: function() { let fn = () => { console.log(this); } fn(); }, hobby: () => { console.log(this); } }; person.skill(); // {name: "leo", skill: ƒ, hobby: ƒ} /* 因为person本身是没有作用域的,故 箭头函数要往更外层寻找,所以找到 Window对象 */ person.hobby(); // Window对象箭头函数没有原型属性
prototypelet fn = () => { return 1; } console.log(fn.prototype); // undefined箭头函数不能当做
Generator函数,不能使用yield关键字
手动实现call、apply、bind(如何改变普通函数中的this指向)
/*
模拟实现call
*/
Function.prototype.myCall = function(obj){
// 这里就是传入的第一个参数
let curObj = obj ? obj : window;
// this是获取调用函数(对象)的引用
// 存储函数的引用到curObj对象中
curObj.fn = this;
// 存储除开第一个参数的数据作为参数数组
let args = [...arguments].slice(1);
// 调用对象方法
let result = curObj.fn(...args);
// 删除对象属性(方法)
delete curObj.fn;
return result;
}
/*
模拟实现apply
*/
Function.prototype.myApply = function(obj) {
let curObj = obj ? obj : window;
curObj.fn = this;
let params = arguments[1] || [];
let result = curObj.fn(...params);
delete curObj.fn;
return result;
}
/*
模拟实现bind
*/
Function.prototype.myBind = function(obj) {
let curObj = obj ? obj : window;
curObj.fn = this;
let params = [...arguments].slice(1);
return function() {
let afterParams = [...arguments];
let resParams = params.concat(afterParams);
let result = curObj.fn(...resParams);
delete curObj.fn;
return result;
};
}
function foo(){
console.log(this);
return 'stronger heart';
}
foo(); // Window
foo.call({name: 'leo'}); // {name: "leo"}
foo.myCall({name: 'great man'}, 'man', 'cool') // {name: "great man"}
foo.myApply({name: 'handsome boy'}, ['code', 'dance']) // {name: "handsome boy"}
let res = foo.myBind({name: 'cool guys'}, 1, 2)('boy'); // {name: "cool guys"}
console.log(res); // stronger heart
==和===的区别
==只是比较值(会做一个隐式的类型转换),而===会比较值与类型(只有两个条件都相同,才会判断为true)
var a = "2";
if(a == 2) {
console.log('这就是==');
console.log(typeof a);
}
if(a == "2") {
console.log('这就是==, too');
console.log(typeof a);
}
if(a === 2) {
console.log('这就是全等');
}
// 这就是==
// string
// 这就是==, too
// string
手动实现扁平化(JS实现数组扁平化)
// 手写扁平化
let arr = [1,2,[3,[4,[5,6]]]];
function myFlat(array) {
let result = [];
for(let ele of array) {
if(typeof ele != 'object') {
result.push(ele);
}else if(Array.isArray(ele)) { // 判断元素是否是数组
// 递归调用
let arr = myFlat(ele);
result.push(...arr);
}
}
return result;
}
console.log(myFlat(arr)); // [1, 2, 3, 4, 5, 6]
let arr = [1,2,[3,[4,[5,6]]]];
// 要求将数组扁平化处理 [1,2,3,4,5,6]
// 方式一: Array.flat(参数) 参数:深度
console.log(arr.flat(1)); // [1, 2, 3, Array(2)]
console.log(arr.flat(2)); // [1, 2, 3, 4, Array(2)]
console.log(arr.flat(3)); // [1,2,3,4,5,6]
console.log(arr.flat(Infinity)); // [1,2,3,4,5,6]
// 方式二:reduce() + 递归调用
function flatFn(arr) {
return arr.reduce((pre,val) => {
return pre.concat(Array.isArray(val) ? flatFn(val) : val);
},[])
}
console.log(flatFn(arr)); // [1,2,3,4,5,6]
// 方式三 数组转成字符串,再将字符串转为数组
function flatFn2(arr) {
return arr.join(',').split(',').map(val => {
// return Number(val);
return parseInt(val);
})
}
console.log(flatFn2(arr)); // [1,2,3,4,5,6]
// 方式四 扩展运算符
function flatFn3(arr) {
while(arr.some(val => Array.isArray(val))) {
arr = [].concat(...arr);
}
return arr;
}
console.log(flatFn3(arr)); // [1,2,3,4,5,6]
不用promise.all,如何判断三个请求都执行完成(只使用Promise)
查看下面的手写 Promise.all
数组去重
Set
let arr = [1, 1, 2, 'leo', 'leo', true, true];
let res = Array.from(new Set(arr));
console.log(res); // [1, 2, 'leo', true]
Map
let arr = [1, 1, 2, 'leo', 'leo', true, true, 2];
let res = [];
let map = new Map();
for (let i = 0; i < arr.length; i++) {
if(map.has(arr[i])) {
map.set(arr[i], true);
}else {
map.set(arr[i], false);
res.push(arr[i]);
}
}
console.log(res); // [1, 2, 'leo', true]
indexOf
let arr = [1, 1, 2, 'leo', 'leo', true, true, 2];
let res = [];
for(let i = 0; i < arr.length; i++) {
if(res.indexOf(arr[i]) === -1) {
res.push(arr[i]);
}
}
console.log(res); // [1, 2, 'leo', true]
sort
let arr = [1, 1, 2, 'leo', 'leo', true, true, 2];
arr.sort(); // [1, 1, 2, 2, 'leo', 'leo', true, true]
let res = [arr[0]];
for(let i = 1; i < arr.length; i++) {
if(arr[i] !== arr[i - 1]) {
res.push(arr[i]);
}
}
console.log(res); // [1, 2, 'leo', true]
函数的节流和防抖
函数的节流
控制高频事件执行次数,将执行次数稀释
var throttle = function(fn, interval) {
// 记录函数引用
let _self = fn;
// 设定定时器
let timer = null;
return function() {
var args = arguments;
if(timer) {
return false;
}
timer = setTimeout(() => {
clearTimeout(timer);
timer = null;
fn.apply(this, args);
}, interval || 500)
}
}
window.onresize = throttle(function() {
console.log(1);
},2000)
通过改变窗口大小,我们可以发现1不会特别一直持续打印,而是在2000ms之内才会执行一次
通过节流的代码,我们可以减少浏览器对单一事件的响应次数,提高工效
函数的防抖
用户触发事件频繁,==只要最后一次==
let input = document.querySelector('input');
let inputEvent = function(fn, interval) {
// 设定计时器
let timer = null;
return function() {
// 前面有就清掉(清除前一次的输入计时器)
if(timer !== null) {
// 此时销毁了timer指针指向的计时器,而timer本身的标记号还没消除
clearTimeout(timer);
}
// timer此时被赋值新的标记号和指向新建的计时器
timer = setTimeout(() => {
// 实现业务代码(注意这里的this,是需要传入的)
fn.call(this);
},interval || 1000)
}
};
input.oninput = inputEvent(function() {
console.log(this.value);
}, 500);
async/await 实现原理(Promise与生成器的语法糖)(待解决!!!!!)
待解决!!!!!
const赋值的引用类型可以被改变(只是地址值不能改变)
想要修改一开始就赋值基础数据类型的 const 声明的变量是会报错的
const same = 'good code';
same = 123; // 报错:Assignment to constant variable.
如果只是修改 const 声明的引用类型的熟悉是 ok 的
const obj = {
name: 'leo',
age: 20
};
// 修改对象的属性
obj.name = 'cool guy';
console.log(obj); // name: 'cool guy', age: 20}
但是如果是给其变量重新赋值一个新对象是会报错的
const obj = {
name: 'tim'
};
// 赋值新对象
obj = {
name: 'Bob'
};
// 报错:Assignment to constant variable.
JS中有哪些继承
组合继承
就是原型链和盗用构造函数的结合体
/*
组合继承
存在的问题:调用两次 Animal 构造函数,为 Dog.prototype 增加了许多无用属性
*/
function Animal(name, call) {
this.name = name;
this.call = call;
this.body = ['eyes', 'legs', 'mouth'];
}
Animal.prototype.getName = function() {
console.log(this.name);
}
function Dog() {
// 盗用 Animal 构造函数并传参
Animal.call(this, ...arguments);
// 获取最后一个参数
let lastArgs = Array.prototype.pop.call(arguments);
this.legs = lastArgs;
}
// 原型链的核心代码: 继承 Animal
Dog.prototype = new Animal();
Dog.prototype.sayLegs = function() {
console.log(this.legs);
}
let dog1 = new Dog('小黑', '汪汪', 4);
console.log(dog1);
dog1.getName(); // 小黑
dog1.sayLegs(); // 4
原型式继承
Object.create() 方法将原型式继承的概念规范化
/*
原型式继承
适用情况:你有一个对象,想在它的基础上再创建一个新对象。 你需要把
这个对象先传给 object(),然后再对返回的对象进行适当修改
`Object.create()` 方法将原型式继承的概念规范化
*/
// 核心代码
function object(o) {
function Foo() {}
Foo.prototype = o;
// 就是为了让返回的实例指向 Foo 的原型对象
return new Foo();
}
let animal = {
species: '哺乳动物',
body: ['eyes', 'legs']
};
let dog = object(animal);
dog.name = '小黑';
dog.body.push('mouth');
let cat = object(animal);
cat.name = '小咪';
cat.body.push('fur');
console.log(dog); // Foo {name: '小黑'}
console.log(cat); // Foo {name: '小咪'}
console.log(animal); // {species: '哺乳动物', body: ['eyes', 'legs', 'mouth', 'fur']}
寄生式继承
/*
寄生式继承
- 与原型式继承比较接近的一种继承方式是寄生式继承
*/
function object(o) {
function Foo() {}
Foo.prototype = o;
// 就是为了让返回的实例指向 Foo 的原型对象
return new Foo();
}
// 核心代码
function createAnother(original) {
let clone = object(original);
clone.sayHello = function() {
console.log('Hello!!');
}
return clone;
}
let animal = {
species: '哺乳动物',
body: ['eyes', 'legs']
};
let dog = createAnother(animal);
dog.name = 'dr.black';
console.log(dog); // Foo {name: 'dr.black', sayHello: ƒ}
dog.sayHello(); // Hello!!
寄生式组合继承
其中createAnother核心代码的步骤图:

/*
寄生式组合继承
- 解决组合继承调用两次父类构造函数的情况,使子类原型上没有多余属性
- 综合前面的所有继承,最佳实践
*/
function object(o) {
function Foo() {}
Foo.prototype = o;
// 就是为了让返回的实例指向 Foo 的原型对象
return new Foo();
}
// 核心代码
function createAnother(SubType, SuperType) {
let prototype = object(SuperType.prototype); // 创建对象
prototype.constructor = SubType; // 增强对象
SubType.prototype = prototype; // 赋值对象
}
function SuperType(name, age) {
this.name = name;
this.age = age;
this.colors = ['blue', 'red', 'green'];
}
SuperType.prototype.sayName = function () {
console.log(this.name);
};
function SubType() {
SuperType.call(this, ...arguments);
let hobbyArg = Array.prototype.pop.call(arguments);
this.hobby = hobbyArg;
}
// 实现寄生
createAnother(SuperType, SuperType);
SubType.prototype.sayAge = function () {
console.log(this.age);
};
// new 实例
let instance = new SubType('leo', 20, 'dance');
console.log(instance);
// SubType {name: 'leo', age: 20, colors: ['blue', 'red', 'green'], hobby: 'dance'}
数组和伪数组的区别?为什么要设置成伪数组?
数组和伪数组的区别:
// 1. 数组使用 Array.isArray() 返回 true, 而伪数组 Array.isArray() 返回 false
// 2. 数组(对象)的 [[Prototype]] 是 Array.prototype, 而伪数组的 [[Prototype]] 是 Object.prototype
为什么要设置成伪数组?
为了让对象能够使用一些数组的方法,方便编程
let obj = {
name: 'leo',
age: 21,
};
[].push.call(obj, 'new property');
[].push.call(obj, 'new property-2');
console.log(obj); // {0: 'new property', 1: 'new property-2', name: 'leo', age: 21, length: 2}
这里的 length 会根据元素的添加而改变!
说说你经常使用到的array方法
总结:
- 修改原数组: pop push shift unshift splice | reverse sort
- 不修改原数组: slice forEach concat join | map reduce filter some every
pop: 返回删除的数组的尾部元素
push: 返回添加尾部元素后的数组长度
shift: 返回删除的数组的头部元素
unshift: 返回添加头部元素后的数组长度
splice: 返回一个数组( 里面的元素是删除的元素)
reverse: 反转原数组,返回反转后的原数组
sort: 排序原数组, 返回排序后的原数组
slice: 返回一个划分的一个新数组
forEach: 返回值为 undefined
concat: 返回添加元素后的新数组
join: 返回一个字符串
map、 filter: 返回一个新数组
some、 every: 返回一个布尔值
reduce: 返回一个数字类型( number类型)
js数据类型,怎么区别array和object
/*
js数据类型,怎么区别array和object
*/
let arr = [];
let obj = {};
// 1. Array.isArray
console.log(Array.isArray(arr)); // true
console.log(Array.isArray(obj)); // false
// 2. instanceof
console.log(arr instanceof Array); // true
console.log(obj instanceof Array); // false
// 3. 从迭代器的角度(判断是否可迭代)
for(let ele of arr) {
console.log(ele);
}
for(let ele of obj) {
console.log(obj); // 报错
}
// 注意:typeof 判断不了!!!
console.log(typeof arr); // object
console.log(typeof obj); // object
Undefined与Null的区别
一、基本数据类型
在介绍undefined与null之前,我们先来了解一下ECMAScript中的数据类型。在ECMAScript中有六种简单数据类型(也称为基本数据类型): Undefined、Null、Boolean、Number 和 String、Symbol (ES6中引入) 、BigInt。还有一种复杂数据类型——Object。
Undefined和Null都只有一个值,分别对应着undefined和null。这两种不同类型的值,既有着不同的语义和场景,又表现出较为相似的行为。
二、undefined
undefined 的字面意思就是:未定义的值 。这个值的语义是,希望表示一个变量最原始的状态,而非人为操作的结果 。 这种原始状态会在以下 4 种场景中出现:
1、声明一个变量,但是没有赋值
var foo;
console.log(foo); // undefined
访问 foo,返回了 undefined,表示这个变量自从声明了以后,就从来没有使用过,也没有定义过任何有效的值。
2、访问对象上不存在的属性或者未定义的变量
console.log(Object.foo); // undefined
console.log(typeof demo); // undefined
访问 Object 对象上的 foo 属性,返回 undefined , 表示Object 上不存在或者没有定义名为 foo 的属性;对未声明的变量执行typeof操作符返回了undefined值。
补充一下: 对于对象中定义了的属性, 但是没赋值, 默认为空字符串
let obj = {
name,
}
// 定义属性, 但是未赋值, 默认为空字符串
console.log(obj.name); // ""
console.log(typeof obj.name); // string
// 未定义属性
console.log(obj.age); // undefined
3、函数定义了形参,但没有传递实参
//函数定义了形参 a
function fn(a) {
console.log(a); // undefined
}
fn(); //未传递实参
函数 fn 定义了形参 a,但 fn 被调用时没有传递参数,因此,fn 运行时的参数 a 就是一个原始的、未被赋值的变量。
4、使用void对表达式求值
void 0 ; // undefined
void false; // undefined
void []; // undefined
void null; // undefined
void function fn(){} ; // undefined
ECMAScript 明确规定 void 操作符 对任何表达式求值都返回 undefined ,这和函数执行操作后没有返回值的作用是一样的,JavaScript 中的函数都有返回值,当没有 return 操作时,就默认返回一个原始的状态值,这个值就是 undefined,表明函数的返回值未被定义。
因此,undefined 一般都来自于某个表达式最原始的状态值,不是人为操作的结果。当然,你也可以手动给一个变量赋值 undefined,但这样做没有意义,因为一个变量不赋值就是 undefined 。
三、null
null 的字面意思是:空值 。这个值的语义是,希望表示一个对象被人为的重置为空对象,而非一个变量最原始的状态 。 在内存里的表示就是,栈中的变量没有指向堆中的内存对象。
1、一般在以下两种情况下我们会将变量赋值为null
如果定义的变量在将来用于保存对象,那么最好将该变量初始化为null,而不是其他值。换句话说,只要意在保存对象的变量还没有真正保存对象,就应该明确地让该变量保存null值,这样有助于进一步区分null和undefined。
当一个数据不再需要使用时,我们最好通过将其值设置为null来释放其引用,这个做法叫做解除引用。不过解除一个值的引用并不意味着自动回收改值所占用的内存。解除引用的真正作用是让值脱离执行环境,以便垃圾收集器在下次运行时将其回收。解除引用还有助于消除有可能出现的循环引用的情况。这一做法适用于大多数全局变量和全局对象的属性,局部变量会在它们离开执行环境时(函数执行完时)自动被解除引用。
2、特殊的typeof null
当我们使用typeof操作符检测null值,我们理所应当地认为应该返"Null"类型呀,但是事实返回的类型却是"object"。
var data = null;
console.log(typeof data); // "object"
是不是很奇怪?其实我们可以从两方面来理解这个结果:
一方面从逻辑角度来看,null值表示一个空对象指针,它代表的其实就是一个空对象,所以使用typeof操作符检测时返回"object"也是可以理解的。
另一方面,其实在JavaScript 最初的实现中,JavaScript 中的值是由一个表示类型的标签和实际数据值表示的(对象的类型标签是 0)。由于 null 代表的是空指针(大多数平台下值为 0x00),因此,null的类型标签也成为了 0,typeof null就错误的返回了"object"。在ES6中,当时曾经有提案为历史平凡, 将type null的值纠正为null, 但最后提案被拒了,所以还是保持"object"类型。
四、总结
用一句话总结两者的区别就是:undefined 表示一个变量自然的、最原始的状态值,而 null 则表示一个变量被人为的设置为空对象,而不是原始状态。所以,在实际使用过程中,为了保证变量所代表的语义,不要对一个变量显式的赋值 undefined,当需要释放一个对象时,直接赋值为 null 即可。
手写 reduce 方法
Array.prototype.myreduce = function (callback, initValue) {
if (this === null) {
throw new TypeError(
"Array.prototype.reduce called on null or undefined"
);
}
if (!Array.isArray(this)) {
throw new TypeError("not a array")
}
if (typeof callback !== "function") {
throw new TypeError(callback + " is not a function");
}
// 数组为空,并且没有初始值时,抛出异常
if (this.length === 0 && arguments.length < 2) {
throw new TypeError('Reduce of empty array with no initial value')
}
const length = this.length;
let acc = typeof initValue === "undefined" ? this[0] : initValue;
let curIdx = typeof initValue === "undefined" ? 1 : 0;
while (curIdx < length) {
acc = callback(acc, this[curIdx], curIdx, this);
curIdx++;
}
return acc;
}
let arr = [1, '2', 3];
let sum = arr.reduce((pre, cur) => {
return pre + cur;
}, 3);
let sum2 = arr.myreduce((pre, cur) => {
return pre + cur;
}, 3);
console.log(sum); // 423
console.log(sum2); // 423
手写Promise核心代码
/*
- Promise 存在三种状态:1.pending 2.fulfilled 3.rejected
注意的细节:
- 细节一:当func函数中存在异常:需要通过try进行捕获
- 细节二:原生Promise规定then里面的两个参数如果不是函数的话就会被忽略
- 细节三:resolve()和reject()是要在事件循环末尾执行
- 实现链式功能:then返回一个new Promise
*/
class MyPromise {
static PENDING = '待定';
static FULFILLED = '成功';
static REJECTED = '拒绝';
constructor(func) {
// 默认为待定状态
this.status = MyPromise.PENDING;
// 结果参数(不论成功或者拒绝)
this.result = null;
// 创建数组保留then中的函数
this.resolveCallbacks = []; // 保存 resolve 函数
this.rejectCallbacks = []; // 保存 reject 函数
// 细节一:捕获func函数中抛出的异常
try {
// 这里需要使用bind为resolve函数设置this指向
func(this.resolve.bind(this), this.reject.bind(this));
} catch (error) {
this.reject(error);
}
}
resolve(result) {
// 细节三;所以要加上setTimeout
setTimeout(() => {
if(this.status === MyPromise.PENDING) {
this.status = MyPromise.FULFILLED;
this.result = result;
// 执行 resolveCallbacks 数组中的待执行函数
this.resolveCallbacks.forEach(callback => {
callback(result);
})
}
});
}
reject(result) {
// 细节三;所以要加上setTimeout
setTimeout(() => {
if(this.status === MyPromise.PENDING) {
this.status = MyPromise.REJECTED;
this.result = result;
// 执行 rejectCallbacks 数组中的待执行函数
this.rejectCallbacks.forEach(callback => {
callback(result);
})
}
});
}
then(onFulfilled, onRejected) {
// 实现链式功能
return new MyPromise((resolve, reject) => {
// 细节二:需要先判断传入的参数是否是函数(是否会被忽略)
onFulfilled = typeof onFulfilled === 'function' ? onFulfilled : () => {};
onRejected = typeof onRejected === 'function' ? onRejected : () => {};
if(this.status === MyPromise.PENDING) {
// 保留then里的函数,稍后执行(所以通过创建数组来保留函数)
this.resolveCallbacks.push(onFulfilled);
this.rejectCallbacks.push(onRejected);
}
if(this.status === MyPromise.FULFILLED) {
setTimeout(() => {
onFulfilled(this.result);
});
}
if(this.status === MyPromise.REJECTED) {
setTimeout(() => {
onRejected(this.result);
});
}
})
}
}
/*
执行过程:
1. 首先执行同步代码: console.log('1');
2. 接着执行同步代码:console.log('2');
3. 遇到 setTimeout 这一块的异步代码,先跳过
4. 执行 promise.then,通过查阅手写代码,此时的 status 为 pending,
所以先将then的参数(onFulfilled函数和onRejected函数)存入对应
数组(resolveCallbacks数组和rejectCallbacks数组)
5. 再回头执行刚才的 setTimeout 里的代码,首先执行的 resolve('这次一定');
通过查看手写代码,发现这个函数又是异步代码(细节三:resolve()和reject()是要在事件循环末尾执行),
所以先跳过
6. 执行后一步的 console.log('4');
7. 最后执行 resolve('这次一定');,遍历 resolveCallbacks 数组中的待执行函数
*/
console.log('1');
let promise = new MyPromise((resolve, reject) => {
console.log('2');
setTimeout(() => {
resolve('这次一定');
console.log('4');
});
});
promise.then(
result => {console.log(result);},
result => {console.log(result.message);}
)
console.log('3');
// 执行顺序:1 2 3 4 这次一定
这里的第一种情况,可根据上面的解释,一样判断(那就是 resolve(),最后执行,先执行 promise.then() )
// 第一种情况
console.log('1');
let promise = new Promise((resolve, reject) => {
console.log('2');
resolve('这次一定');
});
promise.then(
result => {console.log(result);},
result => {console.log(result.message);}
)
console.log('3');
// 执行顺序:1 2 3 这次一定
// 第二种情况
console.log('1');
let promise = new Promise((resolve, reject) => {
console.log('2');
setTimeout(() => {
resolve('这次一定');
console.log('4');
});
});
promise.then(
result => {console.log(result);},
result => {console.log(result.message);}
)
console.log('3');
// 执行顺序:1 2 3 4 这次一定
要是不懂可以再看一遍:技术蛋老师,手写Promise核心代码
手写Promise.的各个方法
Promise.resolve
Promsie.resolve(value) 可以将任何值转成值为 value 状态是 fulfilled 的 Promise,但如果传入的值本身是 Promise 则会原样返回它。
Promise.resolve = function(value) {
if(value instanceof Promise) {
return value;
}
return new Promise(resolve => resolve(value));
}
Promise.reject
和 Promise.resolve() 类似,Promise.reject() 会实例化一个 rejected 状态的 Promise。但与 Promise.resolve() 不同的是,如果给 Promise.reject() 传递一个 Promise 对象,则这个对象会成为新 Promise 的值。
Promise.reject = function(reason) {
return new Promise((resolve, reject) => {
reject(reason);
})
}
Promise.all
Promise.all 的规则是这样的:
- 传入的所有 Promsie 都是 fulfilled,则返回由他们的值组成的,状态为 fulfilled 的新 Promise;
- 只要有一个 Promise 是 rejected,则返回 rejected 状态的新 Promsie,且它的值是第一个 rejected 的 Promise 的值;
- 只要有一个 Promise 是 pending,则返回一个 pending 状态的新 Promise;
Promise.all = function(promiseArr) {
let count = 0;
let result = [];
return new Promise((resolve, reject) => {
promiseArr.forEach((itemPromise, index) => {
// 这里套不套 Promise.resolve() 都可以
Promise.resolve(itemPromise).then(res => {
// 执行成功的promise数量加1
count++;
/*
将每一个执行成功的promise的值存入数组result,
最后作为resolve的参数返回
*/
result[index] = res;
if(count == promiseArr.length) {
resolve(result);
}
}, reason => {
reject(reason);
})
})
})
}
Promise.race
Promise.race 会返回一个由所有可迭代实例中第一个 fulfilled 或 rejected 的实例包装后的新实例。
Promise.race = function(promiseArr) {
return new Promise((resolve, reject) => {
promiseArr.forEach(itemPromise => {
Promise.resolve(itemPromise).then(res => {
resolve(res);
}, reason => {
reject(reason);
})
})
})
}
Promise.any
Promise.any 的规则是这样:
- 空数组或者所有 Promise 都是 rejected,则返回状态是 rejected 的新 Promsie,且值为 AggregateError 的错误;
- 只要有一个是 fulfilled 状态的,则返回第一个是 fulfilled 的新实例;
- 其他情况都会返回一个 pending 的新实例;
Promise.any = function(promiseArr) {
// 被拒绝的个数
let count = 0;
return new Promise((resolve, reject) => {
if(promiseArr.length == 0) return ;
promiseArr.forEach((promiseItem, index) => {
Promise.resolve(promiseItem).then(res => {
resolve(res);
}, reason => {
count++;
if(count == promiseArr.length) {
reject(new AggregateError('All promises were rejected'));
}
})
});
})
}
Map和WeakMap、Set和WeakSet的区别
流程图原理解析

地址: https://www.processon.com/diagraming/62ee69d16376896d3874458c
Set和WeakSet
let set =new Set(),key={};
set.add(key)
console.log(set.size) //1
//移除原始引用
key=null
console.log(set.size) //1
key=[...set][0] //取回原始引用
WeakSet由来
从上面的例子中发现, 我们移除了原始引用 key 后, 还是可以在 set 中访问到 key 这个引用类型, 是因为 set 存在对这个 key 对象的强引用, 导致我们还能访问到 key, 这样的话会导致内存无法释放, 进而导致内存泄漏. 为了解决这个问题, 可以使用 WeakSet !
WeaKSet的弱引用
因为其弱引用的特性:
WeakSet 成员只能是引用类型
不能使用 for-of、forEach 等 (可以查看其并未实现 Symbol.iterator )
因为弱引用, WeakSet 结构没有
keys(),values(),entries()等方法和size属性
一般使用场景
- WeakSet 适合临时存放一组对象,以及存放跟对象绑定的信息
具体一个场景就是存储DOM对象,当我们存储的DOM对象元素被另外一段脚本移除,我们也不想保留这些元素的引用而造成内存泄漏,就可以使用WeakSet来存储。
const ws = new WeakSet();
document.querySelectorAll("button").forEach(item => Ws.add(item));
Map和WeakMap
Map的key可以是任意类型;WeakMap的key只能是引用类型Map的成员是强引用,垃圾回收需要考虑Map中的引用;而WeakMap的成员是弱引用,垃圾回收不需要考虑WeakMap中的引用;/* Map和WeakMap引用区别 */ let map = new Map(); let obj = { name: 'leo' }; map.set(obj, 'leo') .set(11, 'kang'); obj = null; // 垃圾回收obj console.log(map); // Map(2) {{…} => 'leo', 11 => 'kang'} let wm = new WeakMap(); let obj2 = { name: 'dong' }; wm.set(obj2, 'bro'); obj2 = null; // 垃圾回收obj2 /* 注意:浏览器显示对象内部也许有内容, 这是因为我们不知道垃圾回收的具体启动时间, 所以显示的是还没有垃圾回收的样子 */ console.log(wm); // WeakMap {}
WeakMap的弱引用
WeakMap的key必须是非null的对象,value可以是任意类型
WeaMap对键名(key)是弱引用的,键值(value)是正常引用
不能使用 for-of、forEach 等 (可以查看其并未实现 Symbol.iterator )
因为弱引用, WeakSet 结构没有
keys(),values(),entries()等方法和size属性
一般使用场景
- 存储DOM元素
将一个 DOM 节点作为键名存入该实例,并将一些附加信息作为键值,一起存放在 WeakMap 里面。这时,WeakMap 里面对element的引用就是弱引用,一旦将这个 DOM 节点删除,该element对象就会自动被垃圾回收机制清除,不存在内存泄漏风险。
<body>
<div>bar</div>
<div>foo</div>
</body>
<script>
const wm = new WeakMap();
document
.querySelectorAll("div")
.forEach(item => wm.set(item, item.innerHTML));
console.log(wm); //WeakMap {div => "bar", div => "foo"}
</script>
- 存储私有变量
ES5中我们经常利用立即执行函数的方式来设置私有变量,但问题是私有变量不会随着实例对象的销毁被回收,WeakMap正好可以解决这个问题。
let Person = (function () {
let privateData = new WeakMap();
function Person(name) {
privateData.set(this, {
name
})
}
Person.prototype.getName = function () {
return privateData.get(this).name;
}
return Person;
}())
let person = new Person('leo');
let res = person.getName();
console.log(person); // Person {}
console.log(res); // leo
当调用Person构造函数时,实例就会被添加到WeakMap集合中,键是this, 是实例的弱引用,值是私有属性name的对象, 如果删除实例,私有属性也就随之消失,不会造成内存泄漏。
什么是事件冒泡、事件委托、事件三阶段
事件三阶段
捕获阶段
目标阶段
冒泡阶段(事件在此阶段触发)

事件冒泡
当big、middle、small元素都有事件时,点击内部的small元素,会从内向外(small -> middle -> big)的触发事件
事件委托
其实就是利用了事件冒泡的原理,通过给父级元素添加事件,从而让子级拥有对应的事件
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<!-- 添加li元素 -->
<input type="text" id="content">
<button id="addLi">添加li元素</button>
<ul>
<li>香蕉</li>
<li>西瓜</li>
<li>苹果</li>
</ul>
<script>
/*
实现:点击对应li标签,就删除该li标签
*/
// 方式一:不利用事件委托(新增li需要单独添加删除的事件)
let lis = document.querySelectorAll('li');
let ul = document.querySelector('ul');
for (let i = 0; i < lis.length; i++) {
// 给每一个li元素添加点击事件
lis[i].onclick = function () {
// 删除点击的li节点
ul.removeChild(this);
}
}
/*
方式二:利用事件委托(给父级元素ul添加事件),
这样一来,即使我后期再添加li元素,我就不用再单独
给新增的li元素添加事件
*/
// let ul = document.querySelector('ul');
// ul.onclick = function(e) {
// this.removeChild(e.target);
// }
// 添加新的li元素
let btn = document.querySelector('#addLi');
let inputText = document.querySelector('#content');
btn.onclick = function() {
// 新建li标签
let newLi = document.createElement('li');
newLi.innerText = inputText.value;
ul.appendChild(newLi);
}
</script>
</body>
</html>
addEventListener 的第三个参数
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<div class="container" style="width: 200px;height: 200px;background-color: brown;">
<div class="box" style="width: 100px;height: 100px;background-color: blue;"></div>
</div>
<script>
/*
addEventListener的第三个参数
- 默认为false,指事件在冒泡阶段触发
- true,指事件在捕获阶段触发
*/
let container = document.querySelector('.container');
let box = document.querySelector('.box');
box.addEventListener('click', function () {
console.log('我是box');
}, true)
container.addEventListener('click', function () {
console.log('我是container');
}, true)
</script>
</body>
</html>
手写实现LRU算法
/**
* @param {number} capacity 容器存储容量
*/
var LRUCache = function (capacity) {
// 设置一个Map集合
this.map = new Map();
this.capacity = capacity;
};
/**
* @param {number} key
* @return {number}
*/
LRUCache.prototype.get = function (key) {
if(this.map.has(key)) {
let temp = this.map.get(key);
this.map.delete(key);
this.map.set(key, temp);
return temp;
}else {
return -1;
}
};
/**
* @param {number} key
* @param {number} value
* @return {void}
*/
LRUCache.prototype.put = function (key, value) {
if(this.map.has(key)) {
this.map.delete(key);
}
this.map.set(key, value);
if(this.map.size > this.capacity) {
// 获取头部要删除的key
let headVal = this.map.keys().next().value;
this.map.delete(headVal);
}
};
/**
* Your LRUCache object will be instantiated and called as such:
* var obj = new LRUCache(capacity)
* var param_1 = obj.get(key)
* obj.put(key,value)
*/
ES6的实现方式:【Q249】使用 js 实现一个 lru cache | js,code高频面试题 | 大厂面试题每日一题
导致内存泄漏的情况
意外全局变量
function aa(){ bb = 15; }闭包引起的内存泄漏
被遗忘的计时器 / 回调函数
// setInterval()这个函数若没有设计停止机制的话,它是会一直执行下去的 let a=[] setInterval(function(){ a.push(1) }) // 老版本的ie无法检测到Dom节点之间的循环引用,会导致内存泄漏(新浏览器不会) let element=document.getElementById('button') function onClick(){ element.innerHtml='text' } element.addEventListener('click',onClick)dom引用
let gogo=document.getElementByid('gogo') // 这样删除dom没问题 document.body.removeChild(document.getElementByid('gogo')) // 这样删除有问题,通过引用的gogo对象来删除,会导致内存泄漏 document.body.removeChild(gogo)
自测题: 登录—专业IT笔试面试备考平台_牛客网
事件循环机制(浏览器和node)
对于 Event Loop , 可以参考: https://www.youtube.com/watch?v=8aGhZQkoFbQ
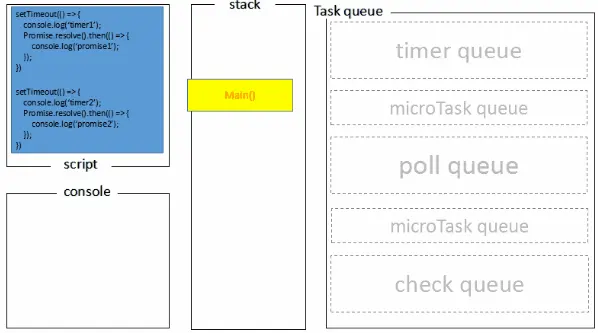
这个视频介绍 js 是一个单线程, 有一个 Call Stack 作为主执行栈, 对同步代码进行执行, 如果在这个过程中遇到了像setTimeout、setInterval、Dom Event、AJAX等这样的异步任务, 会先将任务添加到 WebAPIs中等待, 当异步任务计时完成或返回时, 将被放入 Task Queue 进行等待, 当Call Stack中执行完毕(清理干净)后, 则从Task Queue中取出第一个任务回调函数进行执行
下面通过一段代码进行证明:
let start = Date.now();
/*
即使定时器的等待时间设置为 0ms,
但也是先打印花费了13ms左右的for循环执行时间, why?
因为 callback() 0ms 后从 WebAPIs 被推入到 task queue,
但是由于此时的 satck 中的执行任务没有清空, 所以也不会放入
stack 中执行, 而是要等到 stack 中清理完后才放入执行
*/
setTimeout(function callback() {
console.log('定时器中的打印');
}, 0);
let count = 0;
for (let i = 0; i < 10000000; i++) {
count++;
}
let end = Date.now();
console.log(end - start + 'ms');
/*
除此之外, ajax请求、以及对 Dom event 的执行情况也是这样
*/
打印结果:


浏览器的事件循环机制:

首先整体的JS代码就是一个宏任务, 在这个宏任务执行过程中, 如果遇到微任务就将其加入微任务队列, 遇到宏任务就将其加入宏任务队列, 然后当前JS代码执行完毕就出栈, 然后执行刚才的微任务队列中的所有任务(清空微任务队列), 然后执行渲染操作和worker相关任务, 最后又从头开始循环, 从宏任务队列中取出最前面的任务放入执行栈中执行.
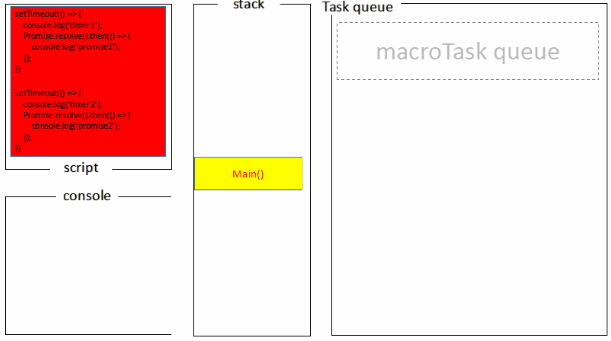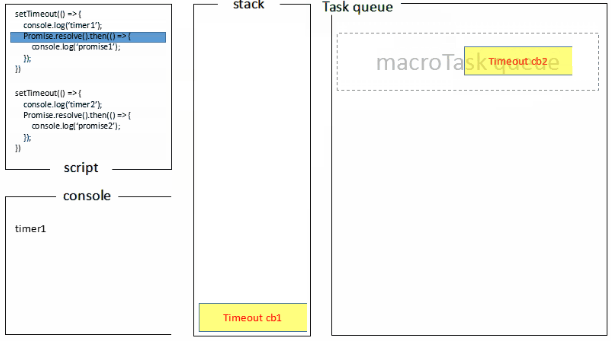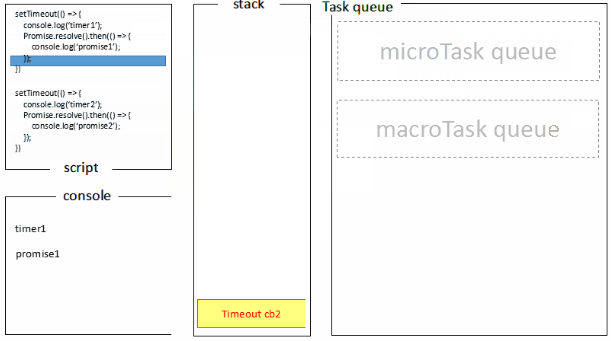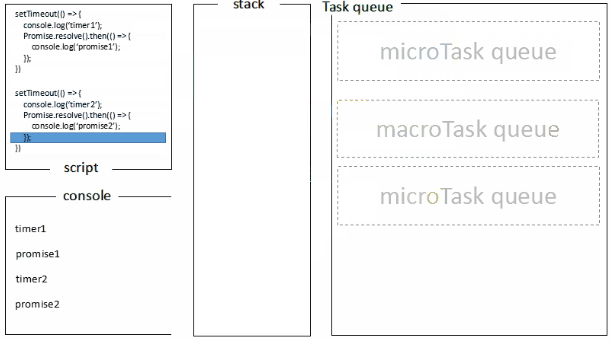
setTimeout(()=>{
console.log('timer1')
Promise.resolve().then(function() {
console.log('promise1')
})
}, 0)
setTimeout(()=>{
console.log('timer2')
Promise.resolve().then(function() {
console.log('promise2')
})
}, 0)
浏览器端运行结果:timer1=>promise1=>timer2=>promise2
node事件循环机制
node事件循环机制和浏览器完全不同, 通过 libuv 引擎分为六个阶段:
poll(incoming) -> check -> close callbacks -> timer -> I/O callbacks -> idle prepare -> poll

其中最主要的三个阶段就是:poll、check、timer
对于刚才的那端代码, 在Node10版本及之前运行流程和结果如下
setTimeout(()=>{
console.log('timer1')
Promise.resolve().then(function() {
console.log('promise1')
})
}, 0)
setTimeout(()=>{
console.log('timer2')
Promise.resolve().then(function() {
console.log('promise2')
})
}, 0)
Node10版本端运行结果:timer1=>timer2=>promise1=>promise2
但是在Node12及以后越来越趋于规范化, 执行结果就同浏览器一样了!!
浏览器和Node事件循环区别

参考: https://zhuanlan.zhihu.com/p/54882306
ES6模块与CommonJS的区别
总结:
ES6模块输出值的引用, CommonJS输出值的拷贝
ES6模块不缓存运行结果, 会动态的去引入文件中取值, 变量总是绑定所在模块; 而CommonJS会缓存结果, 不会动态的去引入模块中取值.
ES6是编译时加载(静态加载只需要的几个方法), CommonJS是运行时加载(加载所有方法)
// CommonJS模块 let { stat, exists, readFile } = require('fs'); // 等同于 let _fs = require('fs'); let stat = _fs.stat; let exists = _fs.exists; let readfile = _fs.readfile;上面代码的实质是整体加载fs模块(即加载fs的所有方法),生成一个对象(_fs),然后再从这个对象上面读取 3 个方法, 这种加载称为“运行时加载”.
import { stat, exists, readFile } from 'fs';上面代码的实质是从fs模块加载 3 个方法,其他方法不加载, 这种加载称为“编译时加载”或者静态加载.
编译时
编译:将源代码翻译成机器能识别的语言(二进制)。计算机还是那个计算机,他至今还是只能看懂01,但随着时间的推移和人类的进步,逐渐出现了很多高级语言,高级语言之所以高级就在于我们可以用一种简单的方式比如if elese 来实现我们的代码逻辑,但最终在执行的时候计算机还是没办法识别的,这个时候就需要一个处理过程"编译",将大家平时写的if else 翻译成机器可以看懂的语言。那负责编译的这部分,我们一般称之为 编译器。
那编译时就会做一些简单的翻译工作,比如检查你有没有粗心写错啥关键字了啊。会进行词法分析,语法分析之类的。就像个老师检查学生的作文中有没有错别字和病句一样.如果发现啥错误编译器就告诉你。开始编译时,如果有errors或者warning信息,都是编译器检查出来的。所谓这时的错误就叫编译时错误,这个过程中做的类型检查也就叫编译时类型检查,或静态类型检查(所谓静态嘛就是没把真把代码放内存中运行起来,而只是把代码当作文本来扫描下)。
运行时
所谓运行时就是代码跑起来了。被装载到内存中去了。(你的代码保存在磁盘上没装入内存之前是个文件。只有跑到内存中才变成活的)。而运行时类型检查就与前面讲的编译时类型检查(或者静态类型检查)不一样。不是简单的扫描代码.而是在内存中做些操作,做些判断以确定我们的程序是否存在错误。
ES6异步加载, CommonJS是同步加载
slice、substring、substr区别
let str = "hello world";
/*
1. slice和substring传入的参数都是start、end; 但是
slice的参数可以是负数, 而substring不行
2. substr的参数传入的是开始索引和要提取的长度
*/
console.log(str.slice(0, 3)); // hel
console.log(str.substring(0, 4)); // hell
console.log(str.substr(0, 2)); // he
/*
-- 对于负数, 重点讲下 --
1. substring (同时传两个参数)
* 都是负数, 则返回空字符串
* 一正一负, 取 [0, 正数 - 1]
2. substr
* 都是负数, 则返回空字符串
* 左正右负, 则返回空字符串
* 左负右正, 首先左边是指 (字符串长度 + 该负数 => 开始下标索引), 右边正数指要提取长度
*/
console.log(str.slice(0, -1)); // hello worl
console.log(str.substring(-7, -5)); // 空字符串
console.log(str.substr(-3, 2)); // rl